
Case Study
From Chaos to Consistency:Creating a Scalable ETL Frameworkon AWS Glue
Author – Parth Pandya
Overview
As organizations scale, managing data pipelines across multiple systems becomes increasingly complex. For us, AWS Glue provided a powerful platform for building ETL jobs—but over time, we began to see a pattern: similar logic was being duplicated across dozens of jobs. Each change required updates in multiple places, slowing us down and introducing risk.
Maintaining slightly different versions of the same logic quickly became a bottleneck. We were solving the same problems repeatedly with minimal code reuse, making the system harder to manage and scale.
To address this, we built a centralized Python-based framework designed to work seamlessly with PySpark in AWS Glue.
The library is version-controlled via GitHub and can be easily imported into Glue jobs, enabling reusability and consistent behavior across our entire data platform. As a result, we’ve eliminated code duplication, improved maintainability, and empowered our engineers to build new data jobs faster—with confidence that they follow established best practices from day one.

Problem Statement
As our data platform scaled, the number of AWS Glue jobs we managed grew significantly. While each job was designed to handle specific data processing tasks, they often shared similar core functionalities—such as extracting data, transforming records, logging, and managing sensitive information like PII.
However, without a shared framework or library, this functionality was implemented separately in each job. Over time, this led to:
Extensive code duplication
Large blocks of similar logic were repeated across multiple scripts, making changes tedious and error-prone
Inconsistent behaviour
code
slight differences in implementation introduced data quality and maintenance issues.
High maintenance overhead:
fixing bugs or adding enhancements required changes in multiple places.
Slower Onboarding:
New engineers had to recreate common logic instead of reusing shared components, slowing them down.
This approach not only made our ETL ecosystem harder to manage but also limited our ability to scale quickly and reliably. We needed a solution that would enforce consistency, reduce redundancy, and accelerate development across our data pipelines.

Solution
To address the challenges of code duplication, maintenance overhead, and inconsistent implementations, we developed a centralized, reusable framework for managing our ETL jobs on AWS Glue. The solution was designed to streamline common tasks, improve maintainability, and enable faster development of reliable and scalable data pipelines.
We created a Python-based library that integrates seamlessly with PySpark in AWS Glue. This library encapsulates essential and commonly repeated ETL logic, making it easy to build new jobs while ensuring consistency across the platform.Key features of the framework include:
Key features
Standardized Logging
Provides consistent and configurable logging across all jobs, enabling easier debugging and monitoring.
Secure Credentials Management
Despite valid SPF, DKIM, and DMARC setups, major inbox providers flagged these emails due to third-party redirects and embedded tracking domains.
PII Handling
Offers built-in methods for encrypting and decrypting sensitive fields, ensuring compliance with data privacy and security policies.
Data Format Handling
Simplifies reading from and writing to common data formats across medallion layers (bronze, silver, gold).
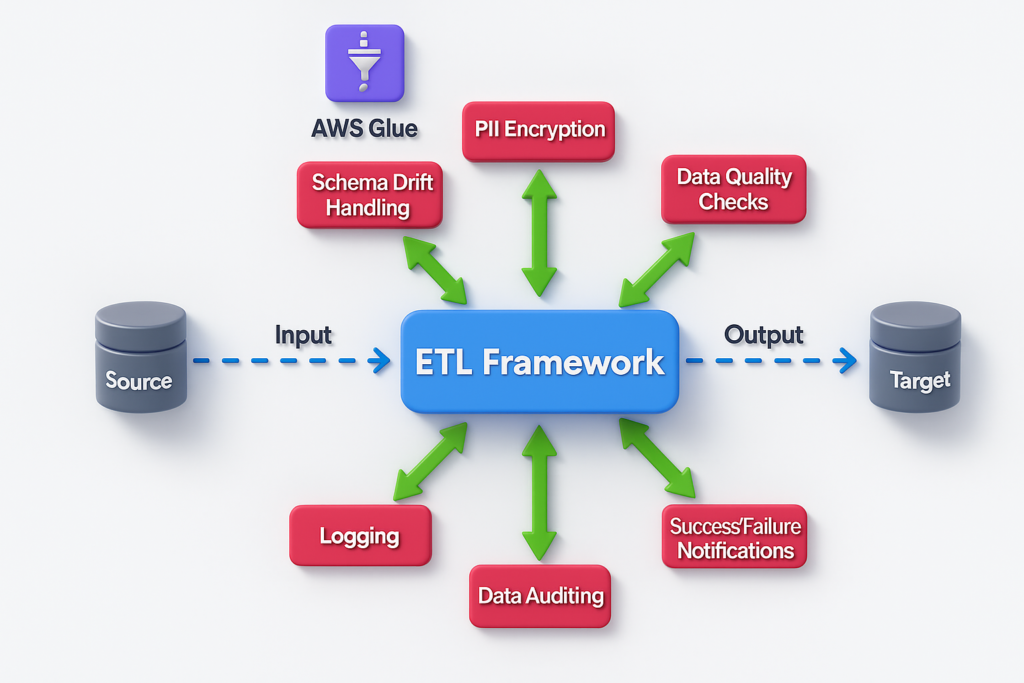
Core Capabilities
Schema Drift Handling
Schema changes at the data source—such as added, removed, or modified columns—are common and can easily break pipelines. Our framework includes a dedicated class to handle schema drift scenarios. It automatically adapts to column additions, deletions, or data type changes without manual intervention, significantly reducing maintenance overhead.
Data Auditing
A built-in auditing mechanism tracks the execution status of every data load, capturing whether the process was successful or failed. This information is stored centrally and can be used to build monitoring dashboards, enabling data teams and stakeholders to validate the integrity of downstream datasets.
Data Quality Checks
A Data Quality module is also implemented that allows engineers to define and run checks after data is ingested—such as row count validations, null value checks, and business rule enforcement. This ensures that the data being moved downstream is both accurate and reliable.
Incremental Load Management
We implemented a watermark-based approach to support incremental data extraction. This allows jobs to process only new or changed records, improving performance and reducing load on the source systems.
Notification System
To ensure visibility and responsiveness, we implemented a notification mechanism that alerts data engineers and business stakeholders
in real-time in the event of pipeline failures. This proactive communication model reduces downtime and builds trust in the data platform.
The library is maintained in a GitHub repository, allowing teams to version, collaborate, and update shared logic efficiently. By importing this library into their Glue jobs, data engineers can quickly develop new pipelines using prebuilt, tested components—focusing only on job-specific transformations and logic.
Framework Delivers:

Benefits Realized & Measured Impact
Implementing the centralized data processing framework led to clear, measurable improvements across our data engineering workflows:
70%
Faster Development
Engineers build jobs quicker by reusing prebuilt components instead of writing boilerplate code.
90%
Reduced Duplication
Common logic is maintained centrally, improving consistency and easing maintenance.
60%
Resilient to Schema Changes
The schema drift handler automatically adapts to changes in source data.
20%
Efficient Incremental Loads
Watermark based logic ensures only new or changed data is processed.
30%
Improved Monitoring
Built-in auditing tracks job status for easy validation and reporting.
100%
Real-Time Alerts
Notifications keep engineers and stakeholders informed of any pipeline failures.
Better Governance
Standardized handling of logging, credentials, and PII improves reliability and compliance.

Conclusion
By developing a reusable, domain-agnostic data processing framework on AWS Glue, we transformed the way our ETL pipelines are built and maintained. What was once a fragmented and repetitive development process is now streamlined, consistent, and scalable.
The framework not only accelerates job development but also ensures high-quality, secure, and maintainable data pipelines.
This solution has laid a strong foundation for future data engineering initiatives, enabling our team to onboard new data sources faster, respond to changes more effectively, and maintain confidence in the reliability of our data platform.