Migration Process
Step 1: Setup Terraform for Azure Databricks
Create a Terraform configuration folder:
versions.tf
terraform {
required_providers {
databricks = {
source = "databricks/databricks"
version = "1.5.0"
}
}
}azure_databricks.tf
provider "databricks" {
host = ${$DATABRICKS_HOST}
token = ${DATABRICKS_TOKEN}
}Initialize Terraform:
terraform initEnsure the terraform-provider-databricks executable is in the same directory.
Step 2: Export Azure Resources
Run the exporter tool:
terraform-provider-databricks exporter \
-skip-interactive \
-services=groups,secrets,access,compute,users,jobs,storage,notebooks \
-listing=jobs,compute,notebooks \
-last-activedays=90 \
-debugThis generates Terraform HCL files for:
- Notebooks
- Clusters
- Jobs
- Secret scopes
- IP access lists
- Groups, Repos, Mounts, etc.
Sanity Checks Post-Migration
- Validate all jobs and clusters are running.
- Check notebook content and mounts.
- Verify secret scopes and access controls.
- Confirm integration with data sources (S3, RDS, etc.)
CI/CD for Databricks Using Terraform
Suggested Structure
- Use a Git-based workflow (e.g., GitHub, GitLab)
- Use Terraform Cloud or CI pipelines for deploy
Sample CI Pipeline Steps
- Lint and format check
terraform initterraform validateterraform plan- Manual approval step
terraform apply
Use workspaces or variables to separate environments (dev, prod).
Summary
Migrating Databricks from Azure to AWS is achievable using Terraform and the experimental resource exporter. With some manual tweaks to instance types, storage mounts, and secrets, you can replicate your entire workspace across clouds.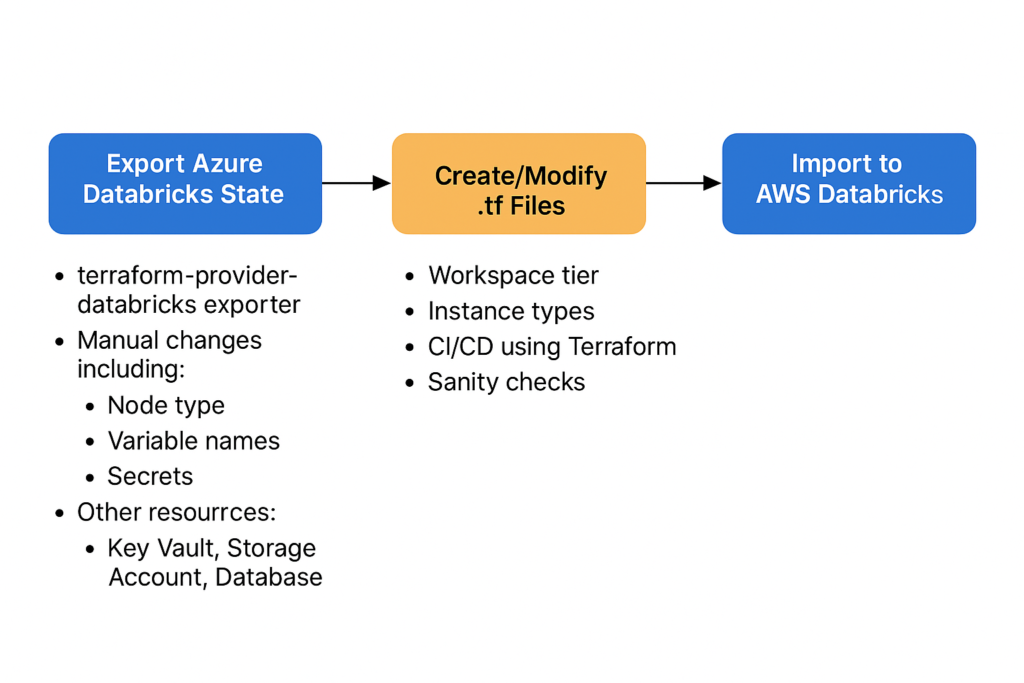
Key Benefits:
- No manual recreation of resources
- Repeatable and version-controlled infrastructure
- CI/CD integration for environment promotion
While the exporter tool is still evolving, it significantly reduces the effort needed for cross-cloud Databricks migration.