
Consider we have two SCD-2 tables item and discount with the following schema. We need to create a single consolidated item table to calculate the price after the discount.

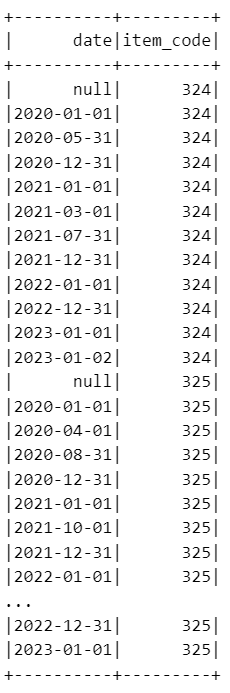
Take care points:
- Make sure you put null valid_to at the end while sorting on the join key.
- Give any max date to null valid_to for all data frames for further calculation.
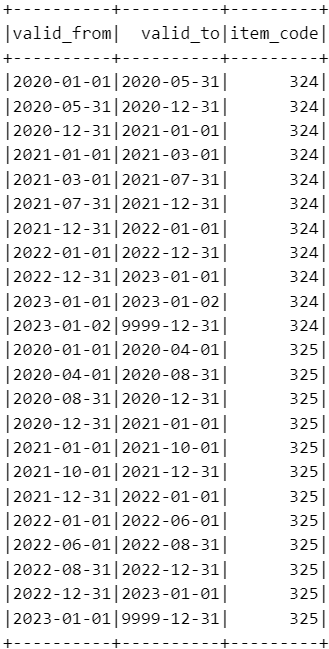
Benefit: This will make a single consolidated table that we can use as a driving table to join other SCD2 tables. The join which was many to many will now become many to one.
Step 4: Once we find the possible distinct date range we can consider that as the primary/driving table and add the required fields from the source (item and discount) tables.
Take care points:
- The join should be on the join key and a date range.
- For the date range consider item/discount table record should fall within any one of the above calculated date range rows.
Benefit: After joining source tables with consolidated date range we will have our desired result and we can do any calculation that needs to be done after joining both SCD2 tables.

Step 5: Implement business requirements over the consolidated SCD2 table. In our example, it’s calculating price after discount.