Data Lake Orchestration: A robust and scalable approach

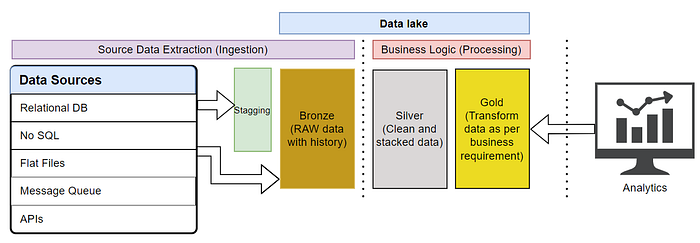
When we design an orchestration to build and populate Data Lake, It is highly recommended to build robust and scalable pipelines for the further possibility of growing & a variety of data, sources, and analytics needs.
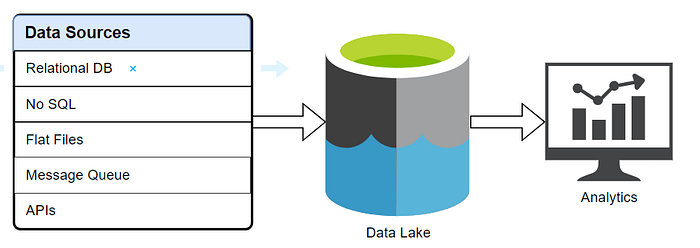
When we consider data flow in any data analytics need there is a high possibility to increase the number of sources, the possibility of increasing data in a data lake and we can have any new requirements from business for the analytics team.
Overall whole data flow can be categorized into 2 parts:
- ETL/ELT: Source to Data lake
- Reporting: Data lake to Analytics Tool
ETL/ELT:
Extract, Transform, and Load are three words that summarise the whole process of orchestrating a data lake.
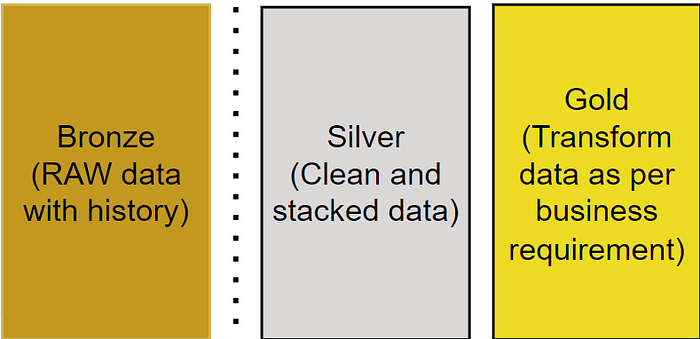
For any data lake, 3 data layers are considered a minimum requirement to make data useful for analytics.
-
Bronze/Raw Layer: A replica of source data with historical records. This layer should have an individual database for each source and each source dataset extraction, there should be one table.
-
Silver/Clean Layer: The latest dataset from bronze in a more clean and validated form. If there are multiple sources for similar datasets (For countries or divisions) this layer can also have stacking for all similar bronze tables from different sources.
-
Gold/Reporting Layer: The gold/reporting layer should contain data, databases, and tables as it is required for analytics to fulfill business needs
Despite above three layer some times we need some stagging in between this layers for cleanup & data validation. It is recommended to keep them as materialised views.
Takeaway (Key points):
Do not consider extraction and transformation as one process. There should be a separate job executing in a separate pipeline. Although it should maintain lineage.
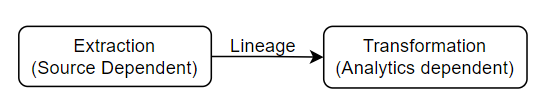
Extraction is a completely source-dependent operation. There should be 1 job for each source. and can trigger batch or have stream based on source.
Transformation is analytics dependent task. We should build Star schema or Snowflake schema as per our business need to server analytics tool a fast and better datasets.
If the source has a fixed schema such as a relational DB or a No SQL with a fixed schema and data type. We should load it directly into a bronze or raw layer. For semi-structured or unstructured data, we should dump it into flat CSV or JSON files and then process it as a batch.Extraction is a completely source-dependent operation. There should be 1 job for each source. and can trigger batch or have stream based on source.

Orchestration
Orchestration is the process of managing, scheduling, and controlling the flow and processing of data through pipelines.
Orchestration is the process of managing, scheduling, and controlling the flow and processing of data through pipelines.
- Extraction: Load data into the data lake from the source.
- Transformation: Create a business model over the data. Preferable to build Star Schema or Snowflake Schema as per the data complexity and relation.
- Dashboard refresh: A schedule or periodic process to get data into an analytics tool.

Although all three are dependent, we can trigger them as per need and dashboard refresh frequency. It is recommended to create a separate pipeline and trigger for the above three actions especially when we have multiple types of source and have different extraction frequencies.
Let’s understand this with use cases
Case 1:
Extraction: Stream, Hourly batch, Daily Batch
Dashboard refresh: Needs to refresh daily.
In this case, there is no meaning in running a transformation pipeline after every source extraction. Therefore Transformation pipeline should also be daily before the dashboard refreshes.
Case 2: Extraction: Stream, Hourly batch, Daily Batch
Dashboard refresh: Needs to refresh every hour.
In this case, too there is no meaning in running a transformation pipeline after every source extraction. Transformation should occur before the dashboard refreshes. Therefore in that case transformation should be hourly.
Case 3:
Extraction: Stream, Hourly batch, Daily Batch
Dashboard refresh: Live Dashboard.
This is a bit different scenario as the dashboard is live, it needs to have the latest data always, but as only a few sources are streaming we should split our pipeline in such a way it will not execute transformation on stale data for the day.
In nut-shell Extraction pipleline should execute based on how offen a new data will arrive or a data at source can change.
While transformation pipeline is not source dependent. It should execute and orchestrated based on dashboard refresh frequency.
And should be splitted in bunch of pipeline if different dashboard refresh at different time.
Why do extraction and transformation as a separate but connected pipeline make the whole orchestration more robust and scalable?
As explained above extraction is a more source-dependent task and transformation depends on reports/business needs. Therefore if any failure happens in any source stream or any changes or new additions in the source. It will not affect the dashboard. Also, transformation is business-dependent so there is no meaning in spending costs on transformation when the business doesn’t need that. These also fill the requirement when we need to keep track of changes at source at any time for the record but want to monitor the daily/hourly performance of the system.